Fra palpasjon til kliniske datamodeller
Som lege er jeg vant til å lytte og bruke hendene. Mesteparten av den informasjonen jeg får, kommer fra disse inn-kanalene. Når kunnskapen skal dokumenteres, så blir de om til 0er og 1ere.
Da jeg begynte i helsevesenet, så jobbet jeg som pleieassistent. Pennene hadde tre farger. En for morgennotat, en for aftennotat og en siste farge for nattnotatet. Mot slutten av vakten førte vi inn dagens hendelser inn i pasientens egen journal. Det er 15 år siden.
Når journalsystemene ble digitale, så fortsatte man å føre journal på samme måte. En snill overgang, uten annen endring enn at man gikk fra penn til tastatur.
Journalen forsto meg aldri
Journalsystemene jeg har brukt, har aldri forstått meg. De har aldri visst hva kunnskapen jeg la inn i innbyggers journal betydde. Og det er sikkert like greit, for skulle jeg forklart all kunnskapen jeg fikk fra samtale og undersøkelse til datamaskinen, så hadde jeg ikke gjort annet enn å klikke. Jeg hadde sikkert klikket.
Men siden dataen ikke forstår meg, så kan heller ikke datamaskinen hjelpe meg. Den kan ikke hjelpe meg med å visualisere blodtrykket, og heller ikke gi meg særlig beslutningsstøtte.
Data med kunnskap om seg selv
For at datamaskiner skal vite noe om hva som blir puttet inn i dem, så trengs detaljerte kliniske modeller (DCM):
En informasjonsmodell utformet for å uttrykke en eller flere kliniske konsept(er) og sammenheng på en standardisert og gjenbrukbar måte, og spesifisere kravene til klinisk informasjon som et adskilt sett med logiske kliniske dataelementer.
ISO 13972
Puuh, tenker vel alle klinikere – og en del andre også. Jeg skal skrive litt framover om hvorfor en passe dose med strukturt informasjon er nyttig for klinikerne.
Et blodtrykk, bare to tall?
De fleste innbyggere går gjennom noen blodtrykksmålinger i løpet av livet. I allefall hos fastlegen, men kanskje også hjemme med eget blodtrykksapparet. I journalen blir det stående som fritekst f eks «BT: 134/83».
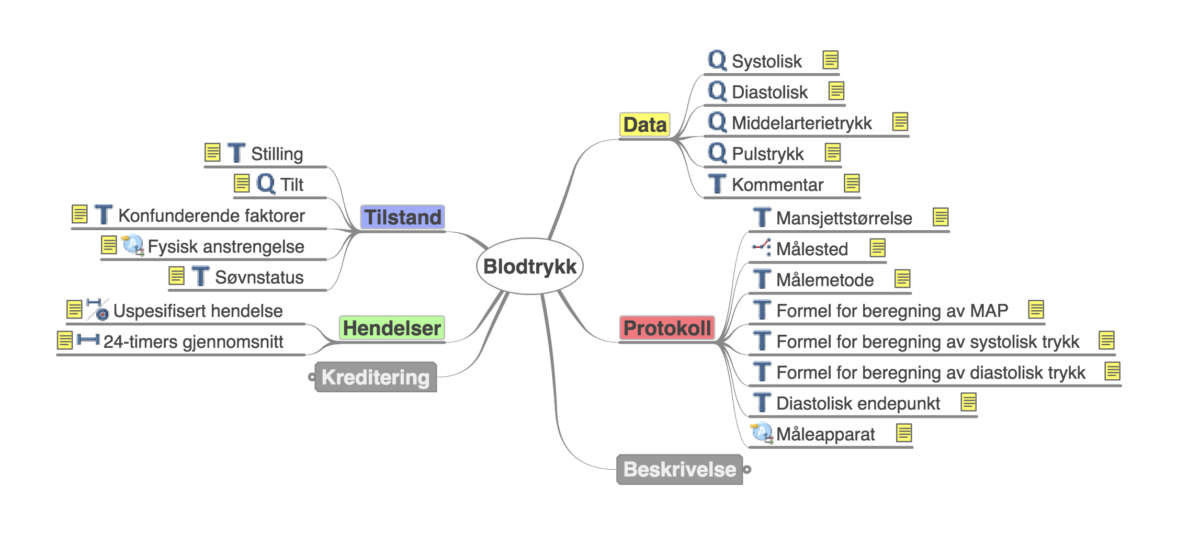
Det er selvsagt en pragmatisk tilnærming til alt som kunne vært dokumentert om blodtrykksmålingen. På arketyper.no finner vi for eksempel denne datamodellen:
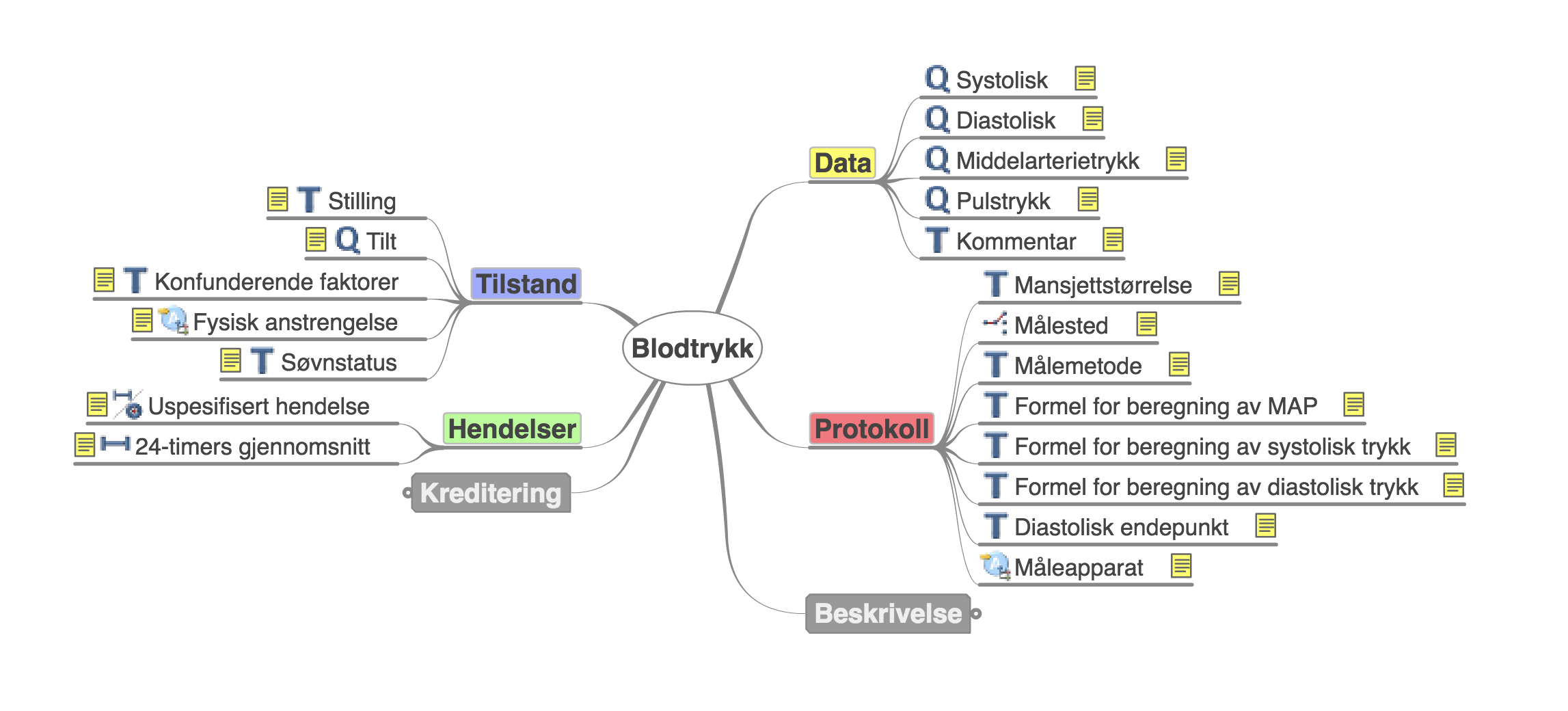
Dette er selvsagt langt flere informasjonsmodeller enn det som trengs til vanlig. Men et godt steg videre var om vi klarte å strukturere systolisk og diastolisk blodtrykk. Og innleggingen av informasjon om at det er en helt vanlig blodtrykksmålingen på kontoret, bør være nettopp å bare skrive «BT: 134/83, vanlig».
Eller at blodtrykksapparetet bare la inn informasjonen selv i journalen. Inkludert hva apparatet het.
Hvorfor strukturerte opplysninger?
Det skal jeg også skrive en del mer om framover. Men la oss ta eksemplet med blodtrykk, der kan vi se for oss det som grunnlag for
- Økt datakvalitet (men også redusert datakvalitet, hvis det gjøres slik at folk ikke gidder)
- Trender og grafer. La meg se utviklingen av blodtrykket. Hvor ofte er det forhøyet sammenliknet med intervensjonsgrensene
- Vis meg hvilke målinger som er vanlig kontortrykk, og hvilke som er 24timers blodtrykk
- Grunnlag for beslutningsstøtte.
- Grunnlag for automatisk innrapportering av data til kvalitets- og forskningsregistre
Litteratur
- HL7. Detailed Clinical Models.
- International Organization for Standardization. Health informatics: detailed clinical models, characteristics and processes. Geneva, Switzerland: International Organization for Standardization; 2014. (ISO/PRF TS 13972)
- Gossen. Detailed Clinical Models: Representing Knowledge, Data and Semantics in Healthcare Information Technology. Healthc Inform Res. 2014. Doi: 10.4258/hir.2014.20.3.163